

O que é Machine Learning?
Machine Learning (ML) é um ramo da Inteligência Artificial que se concentra no desenvolvimento de algoritmos e técnicas que permitem aos computadores aprender e melhorar seu desempenho em uma tarefa específica, sem serem explicitamente programados.
Através do uso de dados e exemplos, os sistemas de ML são capazes de identificar padrões, fazer previsões e tomar decisões de forma autônoma. Alguns exemplos atuais incluem modelos de LLM, como o ChatGPT, Gemini, Claude 3, entre outros.
A importância do Machine Learning nos dias atuais
Nos últimos anos, o Machine Learning tem se tornado cada vez mais relevante em diversos setores, desde a indústria até a área da saúde.
Com o aumento exponencial da quantidade de dados gerados diariamente, o ML se tornou uma ferramenta essencial para extrair insights valiosos e automatizar processos complexos.
Empresas de todos os tamanhos estão investindo em tecnologias de aprendizado de máquina para otimizar suas operações, melhorar a experiência do cliente e obter vantagens competitivas.
Benefícios do Machine Learning para empresas e sociedade
A aplicação do Machine Learning traz uma série de benefícios para as empresas e a sociedade na totalidade. Alguns desses benefícios incluem:
- Automação de tarefas repetitivas e complexas
- Melhoria na tomada de decisões baseada em dados
- Personalização de produtos e serviços
- Detecção de fraudes e anomalias em tempo real
- Avanços na pesquisa médica e diagnósticos precisos
- Otimização de processos industriais e cadeias de suprimento
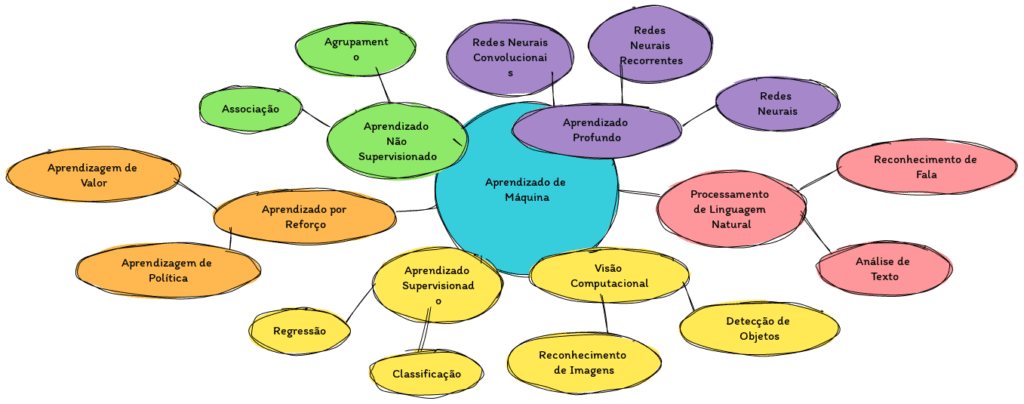
Fundamentos do Machine Learning
Aprendizado Supervisionado vs Não-Supervisionado
Existem dois principais tipos de aprendizado em Machine Learning: supervisionado e não-supervisionado. No aprendizado supervisionado, o modelo é treinado com dados rotulados, onde tanto as entradas quanto as saídas desejadas são fornecidas. O objetivo é aprender a mapear as entradas para as saídas corretas.
Já no aprendizado não-supervisionado, o modelo recebe apenas os dados de entrada, sem rótulos, e deve encontrar padrões e estruturas ocultas por conta própria.
Principais algoritmos de Machine Learning
Existem diversos algoritmos utilizados em Machine Learning, cada um com suas características e aplicações específicas. Alguns dos principais algoritmos incluem:
Regressão Linear
A Regressão Linear é um algoritmo simples e amplamente utilizado para prever valores contínuos com base em variáveis independentes. Ele encontra a melhor linha reta que se ajusta aos dados, minimizando a soma dos erros quadráticos.
Regressão Logística
A Regressão Logística é utilizada para problemas de classificação binária, onde o objetivo é prever a probabilidade de um evento ocorrer. Ela aplica uma função sigmoide para mapear as entradas em um valor entre 0 e 1.
Árvores de Decisão
As Árvores de Decisão são modelos de aprendizado supervisionado que dividem recursivamente os dados em subconjuntos com base nos valores dos atributos. Elas são fáceis de interpretar e podem lidar com dados categóricos e numéricos.
Máquinas de Vetores de Suporte (SVM)
As Máquinas de Vetores de Suporte são algoritmos poderosos para classificação e regressão. Elas tentam encontrar um hiperplano que separe as classes com a maior margem possível, lidando bem com dados de alta dimensionalidade.
Redes Neurais Artificiais
As Redes Neurais Artificiais são modelos inspirados no funcionamento do cérebro humano. Elas consistem em camadas de neurônios interconectados que aprendem a mapear as entradas para as saídas através de um processo iterativo de ajuste de pesos.

Processo de treinamento de modelos de Machine Learning
O processo de treinamento de um modelo de Machine Learning envolve várias etapas:
- Coleta e preparação dos dados
- Divisão dos dados em conjuntos de treinamento, validação e teste
- Escolha e configuração do algoritmo apropriado
- Treinamento do modelo com os dados de treinamento
- Avaliação do desempenho do modelo nos dados de validação
- Ajuste de hiper parâmetros e retreinamento, se necessário
- Teste final do modelo nos dados de teste para estimar seu desempenho em dados não vistos
Avaliação de performance de modelos
A avaliação da performance dos modelos de Machine Learning é crucial para garantir sua eficácia e confiabilidade. Algumas métricas comuns utilizadas incluem:
- Acurácia: proporção de previsões corretas em relação ao total de previsões
- Precisão: proporção de verdadeiros positivos em relação aos positivos previstos
- Recall: proporção de verdadeiros positivos em relação aos positivos reais
- F1-Score: média harmônica entre precisão e recall
- Matriz de Confusão: tabela que resume o desempenho do modelo em termos de verdadeiros positivos, falsos positivos, verdadeiros negativos e falsos negativos
Pré-processamento de Dados
Importância da qualidade dos dados
A qualidade dos dados é um fator determinante para o sucesso dos projetos de Machine Learning. Dados inconsistentes, incompletos ou enviesados podem levar a modelos imprecisos e decisões equivocadas. Portanto, é essencial investir tempo e esforço na coleta, limpeza e preparação adequada dos dados antes de iniciar o treinamento dos modelos.
Limpeza e tratamento de dados
A limpeza e o tratamento dos dados envolvem uma série de tarefas, como:
- Remoção de duplicatas e valores ausentes
- Correção de erros e inconsistências
- Padronização de formatos e unidades de medida
- Identificação e remoção de outliers (valores discrepantes)
- Encodificação de variáveis categóricas
Transformações de variáveis
Em muitos casos, é necessário aplicar transformações nas variáveis para melhorar o desempenho dos modelos de Machine Learning. Algumas transformações comuns incluem:
- Logarítmica: reduz a escala de variáveis com valores muito altos
- Potência: lineariza relações não-lineares entre variáveis
- One-Hot Encoding: converte variáveis categóricas em binárias
- Binning: agrupa valores contínuos em intervalos discretos
Engenharia de Features
A Engenharia de Features é o processo de criar novas variáveis (features) a partir das existentes, a fim de fornecer informações mais relevantes para os modelos de Machine Learning. Algumas técnicas de Engenharia de Features incluem:
- Combinação de variáveis existentes
- Extração de informações temporais (ex: dia da semana, mês, ano)
- Criação de variáveis baseadas em conhecimento de domínio
- Aplicação de transformações não-lineares (ex: polinomiais)
Normalização e Padronização
A normalização e a padronização são técnicas utilizadas para colocar as variáveis em uma escala similar, evitando que algumas delas dominem o modelo devido à sua magnitude. A normalização redimensiona os valores para um intervalo específico (geralmente entre 0 e 1), enquanto a padronização subtrai a média e divide pelo desvio padrão, resultando em uma distribuição com média 0 e desvio padrão 1.
Aplicações Práticas de Machine Learning
Detecção de Fraudes
O Machine Learning tem sido amplamente utilizado na detecção de fraudes em transações financeiras, seguros e comércio eletrônico. Através da análise de padrões históricos e comportamentais, os modelos são capazes de identificar atividades suspeitas em tempo real, reduzindo perdas e protegendo os consumidores.
Sistemas de Recomendação
Os sistemas de recomendação, presentes em plataformas como Netflix, Amazon e Spotify, utilizam algoritmos de Machine Learning para sugerir produtos, serviços ou conteúdo personalizado para cada usuário. Esses sistemas se baseiam no histórico de interações, preferências e similaridades entre usuários para fazer recomendações relevantes e melhorar a experiência do cliente.
Reconhecimento de Imagem e Visão Computacional
O reconhecimento de imagem e a visão computacional são áreas em que o Machine Learning tem apresentado avanços significativos. Através de técnicas como Redes Neurais Convolucionais (CNNs), os modelos são capazes de identificar objetos, rostos, cenas e até mesmo diagnosticar doenças a partir de imagens médicas.
Processamento de Linguagem Natural
O Processamento de Linguagem Natural (PLN) é uma área do Machine Learning que lida com a interação entre computadores e linguagem humana. Aplicações comuns incluem análise de sentimento, tradução automática, chatbots e sumarização de textos. Modelos como Redes Neurais Recorrentes (RNNs) e Transformers têm impulsionado avanços significativos nessa área.
Veículos Autônomos
O desenvolvimento de veículos autônomos é uma das aplicações mais empolgantes e desafiadoras do Machine Learning. Através da combinação de técnicas como visão computacional, aprendizado por reforço e fusão de sensores, os veículos autônomos são capazes de perceber o ambiente ao seu redor, tomar decisões em tempo real e navegar de forma segura em situações complexas.
Desafios e Considerações
Viés e Justiça em Machine Learning
Um dos principais desafios em Machine Learning é garantir que os modelos sejam justos e não perpetuem ou amplifiquem vieses existentes nos dados. É essencial identificar e mitigar possíveis fontes de viés, como sub-representação de certos grupos demográficos nos dados de treinamento ou variáveis proxy que possam levar a decisões discriminatórias.
Deploy e Monitoramento de Modelos em Produção
Levar um modelo de Machine Learning para produção envolve uma série de desafios técnicos e operacionais. É necessário considerar aspectos como escalabilidade, latência, integração com outros sistemas e monitoramento contínuo. O monitoramento dos modelos em produção é essencial para detectar anomalias, degradação de desempenho e necessidade de retreinamento.
O Futuro do Machine Learning

Tendências e avanços recentes
O campo do Machine Learning está em constante evolução, com novas técnicas e abordagens sendo desenvolvidas regularmente. Algumas tendências e avanços recentes incluem:
- Aprendizado por reforço: permite que os agentes aprendam através da interação com o ambiente, recebendo recompensas ou penalizações.
- Aprendizado federado: permite treinar modelos em dados distribuídos, sem a necessidade de centralizar os dados.
- Modelos pré-treinados e fine-tuning: uso de modelos grandes e genéricos pré-treinados em grandes quantidades de dados, que podem ser adaptados para tarefas específicas com menos dados.
- Modelos generativos (GANs e VAEs): capazes de gerar novos dados sintéticos similares aos dados de treinamento.
Impacto na força de trabalho e sociedade
O avanço do Machine Learning terá um impacto significativo na força de trabalho e na sociedade como um todo. Alguns empregos serão automatizados, enquanto outros serão criados, exigindo novas habilidades e conhecimentos. Será fundamental promover a educação e o treinamento em Machine Learning para preparar a força de trabalho para essa transição. Além disso, será necessário abordar questões éticas e sociais relacionadas ao uso responsável e transparente da tecnologia.
Áreas promissoras para aplicação de ML
Existem diversas áreas promissoras para a aplicação de Machine Learning no futuro, incluindo:
- Saúde: diagnóstico precoce de doenças, descoberta de novos medicamentos e medicina personalizada.
- Sustentabilidade: otimização do uso de recursos, previsão de eventos climáticos extremos e monitoramento ambiental.
- Educação: personalização do aprendizado, identificação de dificuldades dos alunos e adaptação de conteúdo.
- Cidades inteligentes: otimização do tráfego, segurança pública e gestão de recursos.
Conclusão
Importância de aprender Machine Learning
Aprender Machine Learning é essencial para profissionais de diversas áreas, não apenas para aqueles diretamente envolvidos com o desenvolvimento de modelos. Compreender os conceitos básicos de ML permite participar de discussões estratégicas, tomar decisões informadas e identificar oportunidades de aplicação da tecnologia. Além disso, o conhecimento em Machine Learning se tornou uma habilidade valiosa no mercado de trabalho, com demanda crescente por profissionais capacitados.
Próximos passos para se aprofundar no tema
Para aqueles que desejam se aprofundar no tema de Machine Learning, existem diversas opções disponíveis:
- Cursos online: plataformas como Coursera, edX e Udacity oferecem cursos introdutórios e avançados em ML.
- Livros: “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” de Aurélien Géron e “Pattern Recognition and Machine Learning” de Christopher Bishop são referências clássicas.
- Projetos práticos: participar de competições em plataformas como Kaggle e desenvolver projetos pessoais são excelentes formas de aplicar os conhecimentos adquiridos.
- Comunidades: participar de comunidades online e eventos relacionados a Machine Learning permite trocar experiências, tirar dúvidas e se manter atualizado sobre as novidades da área.
Perguntas Frequentes
O que é necessário para começar a aprender Machine Learning?
Para começar a aprender Machine Learning, é recomendado ter conhecimentos básicos de programação (preferencialmente em Python ou R), matemática (álgebra linear, cálculo e estatística) e familiaridade com manipulação e visualização de dados.
Quais as linguagens de programação mais usadas em ML?
As linguagens de programação mais populares em Machine Learning são Python e R. Python se destaca pela sua ampla gama de bibliotecas de ML, como Scikit-Learn, TensorFlow e PyTorch, enquanto R é amplamente utilizado em análise estatística e possui pacotes poderosos para modelagem.
É preciso ter conhecimentos avançados de matemática e estatística?
Embora um conhecimento sólido de matemática e estatística seja benéfico para entender os fundamentos dos algoritmos de ML, não é estritamente necessário ter conhecimentos avançados para começar a aplicar as técnicas. Muitas bibliotecas e frameworks abstraem grande parte da complexidade matemática, permitindo que os desenvolvedores se concentrem na aplicação prática.
Quanto tempo leva para dominar Machine Learning?
O tempo necessário para dominar Machine Learning varia de acordo com o nível de proficiência desejado e a dedicação do indivíduo. É possível adquirir conhecimentos básicos e começar a aplicar técnicas simples em algumas semanas ou meses. No entanto, para se tornar um especialista em ML, pode levar anos de estudo, prática e experiência em projetos reais.
?")




